微服务学习笔记
微服务架构是一种架构思想,旨在通过将功能分解到各个离散的服务中以实现对解决方案的解耦。它的主要作用是将功能分解到离散的各个服务当中,从而降低系统的耦合性,并提供更加灵活的服务支持。
Spring Cloud微服务
springcloud版本对照 https://github.com/spring-cloud/spring-cloud-release/wiki/Spring-Cloud-Hoxton-Release-Notes
- 微服务是一种架构风格
- 一个应用拆分为一组小型服务
- 每个服务运行在自己的进程内,也就是可独立部署和升级
- 服务之间使用轻量级HTTP交互
- 服务围绕业务功能拆分
- 可以由全自动部署机制独立部署
- 去中心化,服务自治。服务可以使用不同的语言、不同的存储技术
服务拆分
将一个单体架构,按照功能模块进行拆分,拆分为多个服务
拆分的注意事项:
1.每一个微服务不能开发重复的业务
2.微服务之间的数据相互独立,不要访问其他微服务的数据库
3.将自己的业务暴露为接口,供其他微服务调用
一、Eureka注册中心
Eureka解决了调用时的地址问题,调用服务的健康问题,还可以提供负载均衡,自动注册,心跳检测服务健康状态的功能
Eureka中有两类角色:
- 服务端:单独部署的Eureka注册中心
- 记录服务信息
- 心跳监控
- 客户端:每个微服务实例
- 服务提供者:注册自己的信息到Eureka中,每隔30s发送心跳
- 服务消费者:根据服务名称从服务端拉取提供者列表,完成负载均衡,选择一个调用
搭建Eureka注册中心服务端
1.创建moudle由父工程管理依赖,继承父工程版本,引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
2.启动类添加@EnableEurekaServer
3.修改yml文件 (作用:将自己也注册到注册中心,目的是存在多个注册中心时相互通信)
server:
port: 10086
spring:
application:
name: eureka-server
eureka:
client:
service-url:
defaultZone: http://localhost:10086/eureka
搭建Eureka注册中心客户端(注册服务到注册中心)
1.引入客户端依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
2.修改yml文件 (作用:将自己也注册到注册中心,目的是存在多个注册中心时相互通信).
spring:
application:
name: user-service
eureka:
client:
service-url:
defaultZone: http://localhost:10086/eureka
使用注册中心获取服务列表,对服务列表做负载均衡
1.修改原有的localhost:8081 -> 服务名称 user-service
2.在RestTemplate的创建bean的方法上添加@LoadBalanced
在这里负载均衡注解的实现是Ribbon,通过服务名称去解析真实访问地址的也是Ribbon
通过@LoadBalanced拦截RestTemplate的所有请求(LoadBalancerInterceptor)
二、Ribbon负载均衡
修改负载均衡规则
1.通过Bean的方式(全局,不能指定某个服务)
@Bean
public IRule randomRule(){
return new RandomRule();
}
2.通过yml文件方式(可以指定某个服务,采用某种方式进行负载均衡)
'user-service':
ribbon:
NFLoadBalancerRuLeClassName: com.netflix.Loadbalancer.RandomRuLe
Ribbion懒加载问题
懒加载会等到第一个请求来到的时候才会去加载负载均衡的客户端,导致首次访问时间较长的问题
修改为饥饿加载即可解决该问题
饥饿加载配置
ribbon:
eager-load:
enabled: true #开启饥饿加载
clients: 'user-service' #指定饥饿加载的服务
#多个服务时
clients:
- 'user-service'
- 'order-service'
三、Nacos注册中心
阿里巴巴的产品,现在为SpringCloud中的一个组件,相比Eureka功能更丰富
Eureka和Nacos两者对比(仅注册中心功能)
| 共同点 | 区别 |
|---|---|
| 都支持服务注册和服务拉取 | Nacos支持服务端主动检测提供者状态:临时实例采用心跳模式,非临时实例采用主动检测模式 |
| 都支持服务提供者心跳方式做健康检测 | 临时实例心跳不正常会被剔除,非临时实例侧不会被剔除 |
| Nacos支持服务列表变更的消息主动推送模式,服务列表更新更及时 | |
| Nacos集群默认采用AP方式,当集群中存在非临时实例时,采用CP模式;Eureka采用AP方式 |
nacos服务端为单独部署
# 配置java环境
# 启动nacos
/nacos/bin/startup.sh -m standalone
# 查看输出文件打开后台网页
http://192.168.6.66:8848/nacos/index.html
nacos服务注册
<!-- 父工程中引入SpringCloudAlibaba的管理依赖 --->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.5.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- 子工程中引入nacos依赖 --->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
配置注册中心地址
spring:
cloud:
nacos:
discovery:
server-addr: 192.168.6.66:8848
现在nacos属于springcloud的一部分,而springcloud定义了服务注册发现的接口规范,修改起来更简单
Nacos的服务分级存储模型
每一个服务可以创建很多个实例,不同的实例可能分布在不同的地域,为了满足优先匹配同一个地域的服务,按照地域进行划分集群
服务调用尽可能选择本地集群的服务,跨集群调用延迟较高
本地集群不可访问时,再去访问其它集群
配置集群名称
spring:
cloud:
nacos:
discovery:
server-addr: 192.168.6.66:8848
cluster-name: SD
配置Ribbon负载均衡规则
com.alibaba.cLoud.nacos.ribbon.NacosRule
Nacos根据权重负载均衡
通过访问nacos后台编辑对应的实例,修改权重即可 范围 [0 - 1]
灰度升级时可以先上线新的版本承担少量请求,测试稳定性,随后调整正常权重
再将旧版本的权重设置为0,待不接收请求后,关闭旧的服务,灰度完成
命名空间 环境隔离
nacos结构
命名空间 > 组 > 服务/数据 > 集群 > 实例
通过不同的命名空间,将不同的服务隔离起来,一般适用于隔离开发环境和生产环境
配置命名空间
通过Nacos后天创建命名空间,复制ID 配置到服务中去
spring: cloud: nacos: discovery: namespace: 5ba5c782-35ad-479f-b861-76e8121e2dd0
临时实例
临时实例下线只有会被自动销毁,且不会主动检测健康状态
非临时实例由Nacos主动检测健康状态,且不会自动销毁
spring:
cloud:
nacos:
discovery:
ephemeral: false
四、Nacos配置管理
实现配置文件热更新
1.创建配置文件
在Nacos后台创建配置文件
2.统一配置管理
要想配置服务启动时优先读取Nacos配置,需要使用bootstrap.yml进行配置
引入配置管理客户端依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
创建bootstrap.yml文件
spring:
application:
name: user-service
profiles:
active: dev
cloud:
nacos:
server-addr: 192.168.6.66:8848
config:
file-extension: yaml
3.实现热更新
1使用注入属性@Value,在类上加入@RefreshScope注解
2使用@ConfigurationProperties注入的,则自动更新
4.多环境配置
在启动时,服务会读取多个配置文件
读取顺序
ervicename.extension > servicename-profile.extension > local
优先级
servicename-profile.extension >servicename.extension > local
可以将共同的配置加入到前面对应的配置文件中
5.Nacos集群
搭建数据库表结构,实现数据的共享。
配置nacos集群的每一个
将cluster.conf.example 重命名 cluster.conf,并修改application.properties的端口号
在文件末尾添加所有nacos节点的地址,并删除实例的数据
修改application.properties 将数据库的配置写入
spring.datasource.platform=mysql
db.num=1
url username password .....
将所有节点都配置好后,启动 startup (不需要添加参数 默认以集群方式启动)
通过nginx将多个节点的地址进行负载均衡
upstream nacos-cluster{ server {ip}:{port}; ... } server{ listen 80; server_name localhost; location /nacos{ proxy_pass http://nacos-cluster; } }
五、HTTP客户端Feign
1.如何使用
引入Feign依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
在启动类上添加注解
@EnableFeignClients
编写Clients类
@FeignClient("user-service")
public interface UserClient {
@GetMapping("/user/{id}")
User findById(@PathVariable("id") Long id);
}
直接注入调用
@Service
public class OrderService {
@Resource
private OrderMapper orderMapper;
@Resource
private RestTemplate restTemplate;
@Resource
private UserClient userClient;
public Order queryOrderById(Long orderId) {
// 1.查询订单
Order order = orderMapper.findById(orderId);
// 2.调用Feign查询用户信息
User user = userClient.findById(order.getUserId());
order.setUser(user);
// 4.返回
return order;
}
}
关于feign的负载均衡
在feign的依赖中已经集成了Ribbon实现了负载均衡。
Feign的自定义配置
feign.client.config.{scope}.{config}={value}
scope > defalut 全局 /服务名
在一般情况下建议关闭后者Basic
feign.Logger.Level
修改日志级别
包含四种不同的级别:NONE、BASIC、HEADERS、FULLfeign.codec.Decoder
响应结果的解析器
http远程调用的结果做解析,例如解析json字符串为java对象feign.codec.Encoder
请求参数编码
将请求参数编码,便于通过http请求发送feign.Contract
支持的注解格式
默认是SpringMVC的注解feign.Retryer
失败重试机制
请求失败的重试机制,默认是没有,不过会使用Ribbon的重试
Feign连接性能优化
在feign中默认使用的HTTP客户端为URLConnection (不支持连接池)
替代方案:ApacheHttpClient、OKHttp(均支持连接池)
1.引入Feign的HttpClients
<!--httpClient的依赖-->
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-httpclient</artifactId>
</dependency>
2.配置连接池
feign:
httpclient: / okhttp:
enabled: true # 开启feign对HttpClient的支持
max-connections: 200 # 最大连接数
max-connections-per-route: 50 # 每个路径最大连接数
3.Feign最佳实践
1.继承 为Controller定义接口,然后Feign的Client继承该接口即可 (耦合度高)
2.抽取 独立模块,单独管理Client代码,服务引入该模块 (引入的内容多)
推荐抽取单独的模块进行维护
- 创建新的模块如feign-api
- 引入spring-cloud-starter-openfeign依赖并编写client及pojo
- 在需要使用客户端的服务,引入feign-api依赖
- 开启@EnableFeignClients指定对应的包路径然后注入clients对象使用即可
clients 数量少的情况推荐直接指定class 减少创建无用的组件对象
六、Gateway网关
网关的功能: 身份认证、权限校验、负载均衡,限流;
1.搭建网关服务
创建maven服务模块,引入依赖
<dependency>
<grouplId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
2.配置网关路由
server:
port: 10010
spring:
application:
name: gateway
cloud:
nacos:
server-addr: localhost:8848
gateway:
routes:
- id: user-service #路由的ID必须唯一
uri: lb://user-service # 路由的目标地址
predicates: #路由断言
- Path=/user/**
- id: order-service
uri: lb://order-service
predicates:
- Path=/order/**
3.访问测试
略
路由断言工厂 RoutePredicateFactory
处理配置文件中的断言规则字符串转换为路由判断条件
如Path字段会交给 PathRoutePredicateFactory

网关路由过滤器
对路由的请求或相应进行加工处理,配置在路由下的过滤器只对当前路由有效
defaultFilters 对所有的路由都生效
defalutFilters example:
spring:
cloud:
gateway:
default-filters:
- AddResponseHeader=X-Response-Default-Red, Default-Blue
- PrefixPath=/httpbin
全局过滤器
全局过滤器通过接口实现
@Component
public class CustomGlobalFilter implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
log.info("custom global filter");
return chain.filter(exchange);
}
@Override
public int getOrder() {
return -1;
}
}
过滤器的执行逻辑
路由过滤器,DefaultFilter,GlobalFilter
三种过滤器都将通过适配器转换为GatewayFilter,加入集合中,通过order排序
defaultFilter的order与路由过滤器的order都按照生命的顺序从1向后排序(各个作用域单独排序)
如果order值相同将按照 defaultFilter > 路由过滤器 > globalFilter
网关跨域
在微服务中,所有请求都将由Gateway接收,所以需要配置Gateway跨域,但是在Gateway中并不是使用servlet而是webflux进行实现,所以跨域方式有所不同。
spring:
cloud:
gateway:
globalcors: # 全局的跨域处理
add-to-simple-url-handler-mapping: true # 解决options请求被拦截问题
corsConfigurations:
'[/**]':
allowedOrigins: # 允许哪些网站的跨域请求
- "http://localhost:8090"
- "http://www.leyou.com"
allowedMethods: # 允许的跨域ajax的请求方式
- "GET"
- "POST"
- "DELETE"
- "PUT"
- "OPTIONS"
allowedHeaders: "*" # 允许在请求中携带的头信息
allowCredentials: true # 是否允许携带cookie
maxAge: 360000 # 这次跨域检测的有效期
七、Docker 容器技术
基本命令
Dockerfile
Dokcerfile本身是一个文本文件,其中包含一个个的指令,每个指令都会形成一个layer
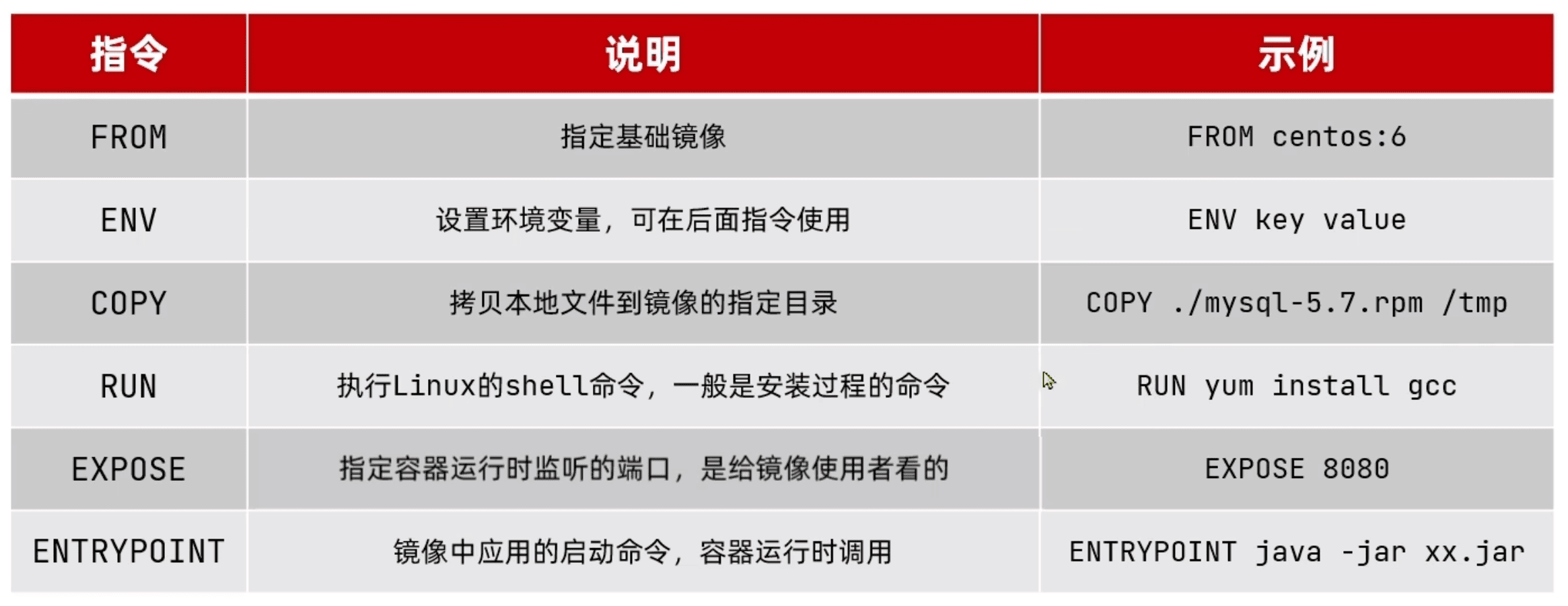
dockerfile示例:
FROM ubuntu:22.04
ENV JAVA_HOME=/usr/local/jdk-17.0.10/
COPY ./target/jdk-17.0.10/ $JAVA_HOME
ENV PATH=$PATH:$JAVA_HOME/bin
FROM jdk17
ENV APPLICATION_DIR=/data
COPY ./target/docker-demo-0.0.1-SNAPSHOT.jar $APPLICATION_DIR/
EXPOSE 8080
ENTRYPOINT java -jar $APPLICATION_DIR/docker-demo-0.0.1-SNAPSHOT.jar
DockerCompose
v1版本需要独立安装compose ,v2版本已经集成到了docker的plugin中
容器编排,快速部署分布式应用
compose文件示例
version: "3.8"
services:
nacos:
image: nacos/nacos-server
environment:
MODE: standalone
ports:
- "8848:8848"
mysql:
image: mysql:5.7
environment:
MYSQL-ROOT-PASSWORD: 123
volumes:
- "mysql-data:/var/lib/mysql"
- "mysql-conf:/etc/mysql/conf.d"
user-service:
build: ./user-service
depends_on:
- nacos
- mysql
- gateway
order-service:
build: ./order-service
depends_on:
- nacos
- mysql
- gateway
gateway:
build: ./gateway
depends_on:
- nacos
ports:
- "10010:10010"
volumes:
mysql-data:
mysql-conf:
私有仓库
创建私有仓库,并设置为docker信任的仓库
镜像:registry、joxit/docker-registry-ui:static
推送: docker tag nginx:latest host:prot/nginx:1.0
docker push
拉取:docker pull host:prot/nginx:1.0
具体操作略
八、异步通讯 - MQ
事件驱动架构:事件通知到broker,broker通知到订阅该事件 的所有服务
异步通讯的优点:消峰,解耦,故障隔离,提升吞吐量
缺点: 对于broker的性能要求较高,价格更复杂,流程线不便追踪
MQ,消息队列也就是事件驱动架构的broker
常见的消息队列软件有:RabbitMQ (可靠稳定性能高),RocketMQ,ActiveMQ,Kafka
RabbitMQ
docker run \
-e RABBITMQ_DEFAULT_USER=reboot \
-e RABBITMQ_DEFAULT_PASS=123456 \
--name mq \
--hostname mq1 \
-p 15672:15672 \
-p 5672:5672 \
-d rabbitmq:3.13.0-management
<img src="https://www.reboots.top/api/file/44c66b59ef6d435e88607544a1e4bfdf.png" alt="image-20240331102749599" style="zoom: 33%;" />
Spring AMQP
通过传统方式使用MQ过于繁琐,Springboot已经为我们提供了自动装配
简单模式示例
1.引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
2.在yml中配置MQ的连接信息
spring:
rabbitmq:
addresses: localhost
port: 5671
virtual-host: /
username: reboot
password: 123456
listener:
simple:
prefetch: 1 //消息预取
3.发送消息到队列
@Resource
private RabbitTemplate rabbitTemplate;
@Test
void name() throws InterruptedException {
String queueName = "simple.queue";
String message = "Hello Spring AMQP";
rabbitTemplate.convertAndSend(queueName,message);
}
3.接收消息
@Component
@Slf4j
public class RabbitMQListener {
@RabbitListener(queues = "simple.queue")
public void listenSimpleQueueMessage(String message) {
log.info(message);
}
}
发布订阅模式
在原有模式中的直接发送到队列改为发送到交换机(exchange),由交换机发送到对应的队列
特点:交换机发送有三种模式: 路由、广播、转发
交换机发送失败后,消息将丢失,交换机不提供存储功能
广播模式
1.定义交换机与队列并进行绑定
bean方式声明
@Configuration
public class FanoutConfig {
@Bean
public FanoutExchange fanoutExchange() {
return new FanoutExchange("wds.fanout");
}
@Bean
public Queue fanoutQueue1() {
return new Queue("fanout.queue1");
}
@Bean
public Binding fanoutBinding1(FanoutExchange fanoutExchange, Queue fanoutQueue1) {
return BindingBuilder
.bind(fanoutQueue1)
.to(fanoutExchange);
}
@Bean
public Queue fanoutQueue2() {
return new Queue("fanout.queue2");
}
@Bean
public Binding fanoutBinding2(FanoutExchange fanoutExchange, Queue fanoutQueue2) {
return BindingBuilder
.bind(fanoutQueue2)
.to(fanoutExchange);
}
}
2.订阅消息
@RabbitListener(queues = "fanout.queue1")
public void listenSimpleQueue1Message(String message) {
log.info("queue1:{}",message);
}
@RabbitListener(queues = "fanout.queue2")
public void listenSimpleQueue2Message(String message) {
log.info("queue2:{}",message);
}
3.发布消息
@Test
void name2() {
String exchangeName = "wds.fanout";
String message = "Hello Spring AMQP by wds";
rabbitTemplate.convertAndSend(exchangeName,"", message);
}
4.成功接收到消息
com.wds.mq.listener.RabbitMQListener : queue2:Hello Spring AMQP by wds
com.wds.mq.listener.RabbitMQListener : queue1:Hello Spring AMQP by wds
路由模式
1.声明队列交换机绑定关系等
注解方式声明
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "direct.queue1"),
exchange = @Exchange(name = "direct.exchange", type = ExchangeTypes.DIRECT),
key = {"blue", "black"}
))
public void listenExchangeDirectMessage(String message) {
log.info("direct queue1:{}", message);
}
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "direct.queue2"),
exchange = @Exchange(name = "direct.exchange", type = ExchangeTypes.DIRECT),
key = {"1", "2"}
))
public void listenExchangeDirectMessage2(String message) {
log.info("direct queue2:{}", message);
}
2.发布消息
@Test
void name3() {
String exchangeName = "direct.exchange";
String message = "Hello Spring AMQP by wds";
rabbitTemplate.convertAndSend(exchangeName,"blue", message);
rabbitTemplate.convertAndSend(exchangeName,"1", message);
}
主题模式
topic和routingkey的区别就是,topic每个单词直接必须有**.**分割
交换机和队列进行绑定时可以使用通配符
#代表零个多个单词
*代码一个单词
使用:
声明:修改交换机为Topic类型 key 改为topic类型的key
其余API没有变化
消息类型转换
在默认情况下,使用jdk默认的序列化方式,可读性差,占用空间大
一般都改为 JSON 类型
1.导入依赖
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
2.创建Bean
@Configuration
public class MessageConfig {
@Bean
public MessageConverter jsonMessageConverter(){
return new Jackson2JsonMessageConverter();
}
}
九、Elasticsearch
一个开源的分布式搜素引擎,可以实现搜索、日志统计、分析、系统监控等功能
- elastic stack
- 是以elasticsearch为核心的技术栈,包括beat、logstash、kibana、elasticsearch
- lucene
- 基于Apache的开源搜索引擎类库,提供了搜索引擎的API
倒排索引
对文档进行提前分词,并对分词建立索引,搜索时通过对搜索条件进行分词,然后根据分词查询出对应的文档。
倒排索引是Elasticsearch搜索引擎的重要原理
创建与启动
创建es网络,方便后面扩展组件
docker network create es-net运行elasticsearch
docker run -d --name es --net es-net --privileged -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -v es-data:/usr/share/elasticsearch/data -v es-config:/usr/share/elasticsearch/config -v es-plugins:/usr/share/elasticsearch/plugins elasticsearch:7.12.1 修改conf中的jvm配置,可以抑制内存占用部署Kibana
docker run -d --name kibana -v kibana-conf:/usr/share/kibana/config --net es-net -p 5601:5601 kibana:7.12.1# 安装ik 分词插件 elasticsearch-plugin install https://github.com/infinilabs/analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip # 重启容器 docker restart es// 使用分词器进行分词 POST /_analyze { "text": "为祖国舔砖Java,我真的谢谢你了", "analyzer": "ik_smart" }analyzer有两种:
ik_smat:智能模式,分词的数量较少。
ik_max_word:详细模式,分词数量较多。
IK分词器 配置
修改/usr/share/elasticsearch/config 或者数据卷 es-config中xml配置文件,修改对应文件并重启es服务器即可生效
可增加词语或停用词语
索引库 Mapping约束
Mapping是对索引库中的文档进行约束,常见的mapping属性有
- type:字段数据类型 (字段的数据类型没有数组的概念,但是可有多个值)
- 字符串:text(可以分词的文本),keyword(精确值,分词无意义)
- 数值: long、integer、short、byte、double、float
- 布尔:boolean
- 日期:date
- 对象:object
- index: 是否创建索引,默认为true
- analyzer:使用哪种分词器创建倒排索引
- properties: 某字段的子字段
- 更多属性参考文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.17/mapping-params.html
索引库操作
# 创建索引库语法
put /索引库名称
{
"mapping": {
"properties": {
"字段名": {
"type": "text",
"analyzer": "ik_smart"
},
"字段名2": {
"type": "keyword",
"index": "false"
},
"字段名3": {
"properties": {
"子字段": {
"type": "keyword",
},
}
}
}
//more ...
}
}
# 创建索引库
PUT /test
{
"mappings": {
"properties": {
"info": {
"type": "text",
"analyzer": "ik_smart"
},
"email": {
"type": "keyword",
"index": false
},
"name": {
"type": "object",
"properties": {
"firstName": {
"type": "keyword",
"index": false
},
"lastName": {
"type": "keyword",
"index": false
}
}
}
}
}
}
# 查询索引库信息
GET /test
# 修改索引库,增加新字段 (不允许修改已有的字段)
PUT /test/_mapping
{
"properties":{
"age":{
"type": "integer"
}
}
}
# 删除索引库
DELETE /test
文档操作
# 新增文档 语法
# 如果不指定ID,将会生成随机的ID,不便查询
POST /索引库名/_doc/文档id
{
"字段1": "值1"
}
# 示例
POST /test/_doc/1
{
"info": "人生苦短我用Java",
"email": "11111@gmail.com",
"name": {
"firstName": "张",
"lastName": "三"
},
"age": 20
}
# 查询文档
GET /test/_doc/1
# 删除文档
DELETE /test/_doc/1
# 修改文档
# 第一种方法 全量修改,该操作会将原有的文档删除,然后新增该文档 (如果ID不存在,则直接新增)
PUT /索引库名/_doc/文档id
{
"字段1": "值1"
}
# 局部修改
POST /test/_update/1
{
"doc":{
"字段1": "新值 "
}
}
RestClient客户端
java使用RestClient操作es
<!-- 对于Springboot项目 必须在参数pom参数中覆盖依赖的版本,否则将会有部分版本不受控制 -->
<elasticsearch.version>7.12.1</elasticsearch.version>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
连接es与索引操作
public class HotelConstants {
public static final String MAPPING_TEMPLATE = "DSLJSON 略"
}
class HotelDemoApplicationTests {
private RestHighLevelClient client;
@BeforeEach
void init() {
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://localhost:9200")
));}
@Test
void test() throws IOException {
System.out.println("client = " + client);}
@Test
void createHotelIndex() throws IOException {
// 1 Create a request object
CreateIndexRequest request = new CreateIndexRequest("hotel");
// 2 Prepare the DSL code
request.source(HotelConstants.MAPPING_TEMPLATE, XContentType.JSON);
// 3 Send the request
client.indices().create(request, RequestOptions.DEFAULT); }
@AfterEach
void destroy() throws IOException {
if (client == null) return;
this.client.close();
}
}
操作文档
新增文档
//添加文档到索引库 1.指定索引库名,文档ID,文档数据 2.发送请求。
IndexRequest request = new IndexRequest("hotel").id("{id}");
request.source("{json_data}",XContentType.JSON);
client.index(request,RequestOptions.DEFAULT);
//通过数据库查询并插入索引库示例
Hotel hotel = hotelService.getById(61083L);
HotelDoc hotelDoc = new HotelDoc(hotel);
// Create an index instance and document ID
IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId() + "");
// Prepare the SL code
request.source(new ObjectMapper().writeValueAsString(hotelDoc), XContentType.JSON);
// Send the request
client.index(request, RequestOptions.DEFAULT);
查询文档
@Test
void testGetDocument() throws IOException {
// 发送查询请求
GetRequest request = new GetRequest("hotel", "61083");
GetResponse documentResponse = client.get(request, RequestOptions.DEFAULT);
// 获取查询结果
String json = documentResponse.getSourceAsString();
System.out.println("json = " + json);
HotelDoc hotelDoc = new ObjectMapper().readValue(json, HotelDoc.class);
System.out.println("hotelDoc = " + hotelDoc);
}
批量操作
// 通过Bulk操作减少请求次数,提高整体性能
@Test
void testBulk() throws IOException {
BulkRequest requests = new BulkRequest();
List<Hotel> list = hotelService.list();
for (Hotel hotel : list) {
requests.add(new IndexRequest("hotel").id(hotel.getId() + "")
.source(new ObjectMapper().writeValueAsString(new HotelDoc(hotel)),XContentType.JSON));
}
client.bulk(requests, RequestOptions.DEFAULT);
}
查询操作
void handleResponse(SearchResponse response) throws IOException {
SearchHits searchHits = response.getHits();
TotalHits totalHits = searchHits.getTotalHits();
System.out.println("totalHits = " + totalHits);
for (SearchHit hit : searchHits.getHits()) {
HotelDoc hotelDoc = new ObjectMapper().readValue(hit.getSourceAsString(), HotelDoc.class);
System.out.println(hotelDoc.getName());
}
}
@Test
void testMatchAll() throws IOException {
SearchRequest request = new SearchRequest("hotel");
request.source().query(QueryBuilders.matchAllQuery());
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
handleResponse(response);
}
@Test
void testMatch() throws IOException {
SearchRequest request = new SearchRequest("hotel");
// request.source().query(QueryBuilders.matchQuery("all", "如家"));
// request.source().query(QueryBuilders.multiMatchQuery("酒店","name"));
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.must(QueryBuilders.termQuery("city", "上海"));
boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").lte(250));
request.source().query(boolQueryBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
handleResponse(response);
}
}
排序和分页
@Test
void testSortAndPage() throws IOException {
SearchRequest request = new SearchRequest("hotel");
request.source().query(QueryBuilders.matchAllQuery());
request.source().from(10).size(20);
request.source().sort("price", SortOrder.DESC);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
handleResponse(response);
}
高亮
@Test
void testHighLight() throws IOException {
SearchRequest request = new SearchRequest("hotel");
request.source().query(QueryBuilders.matchQuery("all","如家"));
request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits searchHits = response.getHits();
TotalHits totalHits = searchHits.getTotalHits();
System.out.println("totalHits = " + totalHits);
for (SearchHit hit : searchHits.getHits()) {
Map<String, HighlightField> fields = hit.getHighlightFields();
HighlightField field = fields.get("name");
if (field == null) {return;}
String highLightName = field.getFragments()[0].string();
HotelDoc hotelDoc = new ObjectMapper().readValue(hit.getSourceAsString(), HotelDoc.class);
hotelDoc.setName(highLightName);
System.out.println(hotelDoc.getName() + "\t" + hotelDoc.getPrice());
}
}
聚合
DSL Query基本语法
全文搜索查询
# 语法格式
GET /indexName/_seach
{
"query":{
"type":{
"condition":"value"
}
}
}
# type : match_all 查询所有
{
"query":{
"match_all": {}
}
}
# type : match 匹配某个字段
{
"query":{
"match": {
"all":"如家"
}
}
}
# type : multi_match 匹配某些字段
# (多个字段在查询时,性能较低,建议使用copy_to)
{
"query":{
"match": {
"query":"如家",
"fields":["brand","name","business"]
}
}
}
精确查询
精确查询一般是查找keyword、数值、日期、boolean等类型的字段
term: 根据数值查询
range:根据数值范围查询
# term 查询
GET /hotel/_search
{
"query":{
"term":{
"city":{
"value":"上海"
}
}
}
}
# range 查询
GET /hotel/_search
{
"query":{
"range":{
"price":{
"gte": 1000,
"lte": 3000
}
}
}
}
#gte 大于等于,gt 大于
#lte 小于等于,lt 小于
地理查询
通过经纬度查询
- geo_bounding_box:查询geo_point类型字段在矩形范围内的文档
GET /hotel/_search
{
"query": {
"geo_bounding_box":{
"location":{
"top_left":{
"lat": 31.1,
"lon": 121.5
},
"bottom_right":{
"lat": 30.9,
"lon": 121.7
}
}
}
}
}
- geo_distance: 查询距离某个中心点距离小于某个值的文档
GET /hotel/_search
{
"query":{
"geo_distance":{
"distance":"15km",
"location":"31.21,121.5"
}
}
}
关联度打分算法:
TF 词条频率 (多个分词的得分不够合理)
TF-IDF 逆文档频率 (受词频影响较大)
BM25算法(受词频影响较小)
Function Score Query
通过该方式对某些关联的文档加分
# 为 “如家” 品牌加分
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match": {
"all": "外滩"
}
},
"functions": [
{
"filter": {
"term": {
"brand": "如家"
}
},
"weight": 10
}
],
"boost_mode": "sum"
}
}
}
复合查询 Boolean Query
复合查询的三种类型:
- must 必须匹配
- should 选择性匹配
- must_note 必须补匹配 不参与算分
- filter 必须匹配 但是不参与算分(减少性能消耗)
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "如家"
}}],
"filter": [{
"geo_distance": {
"distance": "10km",
"location": {
"lat": 31.21,
"lon": 121.5
}}}],
"must_not": [
{
"range": {
"price": {
"gte": 400
}}}]}}}
搜索结果处理
排序
elasticsearch支持对搜索结果排序,默认根据_score进行排序
可以排序的类型有,keyword,数值,地理坐标,日期
// 排序写法
GET /indexName/_search
{
"query":{
"match_all":{}
},
"sort":{
"field":"desc" //排序字段和排序方式 ASC和DESC
}
}
// 根据地理坐标排序
GET /hotel/_search
{
"query": {
"match_all": {}
}
, "sort": [
{
"_geo_distance": {
"location": {
"lat": 31.034315,
"lon": 121.611691
},
"order": "asc"
}}]}
分页
通过from参数指定开始的索引,通过size指定获取的文档数 ,当我们不指定分页参数进行查询时,默认只查询前10条数据
GET /hotel/_search
{
"query":{
"match_all":{}
},
"sort":{
"price":"asc"
},
"from":0,
"size":100
}
深度分页
对于分页,es每次都要查出所有的数据再进行截取,对于内存消耗太大,对于查询es限制只能查前10000条数据
对于非常特殊的需求可以通过排序,search_after 查出第10000条,然后将第10000条数据的作为条件,再次查询 或者 scroll(弃用)
高亮
GET /hotel/_search
{
"query": {
"match": {
"all": "如家"
}
},
"highlight": {
"fields": {
"name": {
"require_field_match": "false"
}
}
}
}
聚合
聚合的三种类型:
桶(Bucket) 类型msyql的分组 Term.. Date...
度量(Metric) 类型mysql的聚合函数 Avg、Max、Min、Stats(同时求多个)
管道(Pipeline) 在其他的聚合之上再聚合
聚合数据类型要求:Keyword date boolean 数值
桶聚合 Buckets
三要素:聚合名称 聚合类型 聚合字段
GET /hotel/_search
{
// 对聚合的数据进行限制
"query": {
"range": {
"price": {
"lte": 200
}
}
},
// size 0 不展示文档
"size": 0,
"aggs": {
"brands": {
"terms": {
"field": "brand",
"size": 10, // 聚合数据条数
"order": {
"_count": "desc" //默认排序规则
}
}
}
}
}
度量聚合 Metric
GET /hotel/_search
{
"size": 0,
"aggs": {
"brands": {
"terms": {
"field": "brand",
"size": 10,
"order": {
"scores.avg": "desc" // 根据子聚合的数据进行排序
}
},
"aggs": { // 子聚合 分组后对每个分组进行计算
"scores": { // 子聚合名称
"stats": { // 聚合类型
"field": "score" // 聚合字段
}
}
}
}
}
}
拼音分词器
安装拼音分词器
elasticsearch-plugin install https://github.com/infinilabs/analysis-pinyin/releases/download/v7.12.1/elasticsearch-analysis-pinyin-7.12.1.zip
测试拼音分词器
POST /_analyze
{
"text": ["如家酒店还不错"],
"analyzer": "pinyin"
}
拼音分词器的缺点
- 结果只有拼音
- 拼音是单个的
解决方案
自定义分词器:在es种分词器分为三部分组成:
character filter:对文本进行简单处理,删除或者替换字符等
tokenizer:对文本进行分割,例如:ik_smart等
tokenizer filter:进一步处理例如:大小写转换、拼音处理等
三部分从上至下依次执行。
如何创建自定义分词器
创建自定义分词器需要在创建索引库时,通过settings来配置;
PUT /test
{
“settings":{
"analysis":{
"analyzer":{
"my_analyzer":{
"tokenizer":"ik_max_word",
"filter":"pinyin"
}
}
}
}
}
进一步定制分词器
现在的分词器有很多缺点,要先在生产环境使用,需要进一步定制
PUT /test
{
"settings":{
"analysis":{
"analyzer":{
"my_analyzer":{ //自定义分词器
"tokenizer":"ik_max_word",
"filter":"pinyin_"
}
},
"filter":{
"pinyin_":{
"type":"pinyin", // 配置拼音分词器的参数
"keep_full_pinyin":false,
"keep_joined_full_pinyin":true,
"keep_original":true,
"remove_duplicated_term":true,
"none_chinese_pinyin_tokenize":false
}
}
}
},
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_max_word" // 指定搜索使用的分词器
//搜索时,不适合使用拼音分词,会出现多余的无用信息
}
}
}
}
// 测试索引库中的分词器
POST /test/_analyze
{
"text": ["如家酒店还不错"],
"analyzer": "my_analyzer"
}
自动补全
如果想要自动补全某个字段,该字段的类型应为 completion 类型
completion 数据格式为字符数组
创建自动补全的索引库
PUT test2
{
"mappings": {
"properties": {
"title":{
"type": "completion"
}
}
}
}
填充数据
POST test2/_doc
{
"title": ["Sony", "WH-1000XM3"]
}
POST test2/_doc
{
"title": ["SK-II", "PITERA"]
}
POST test2/_doc
{
"title": ["Nintendo", "switch"]
}
查询补全
GET /test2/_search
{
"suggest": {
"titleSuggest": {
"text": "s",
"completion": {
"field": "title",
"skip_duplicates": true,
"size": 10
}
}
}
}
整合自动补全和拼音分词
GET /hotel/_mapping
DELETE /hotel
PUT /hotel
{
"settings": {
"analysis": {
"analyzer": {
"text_analyzer": {
"tokenizer": "ik_max_word",
"filter": "pinyin_"
},
"completion_analyzer": {
"tokenizer": "ik_smart",
"filter": "pinyin_"
}
},
"filter": {
"pinyin_": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"address": {
"type": "keyword",
"index": false
},
"brand": {
"type": "keyword",
"copy_to": "all"
},
"business": {
"type": "keyword"
},
"city": {
"type": "keyword",
"copy_to": "all"
},
"id": {
"type": "keyword"
},
"isAD": {
"type": "boolean"
},
"location": {
"type": "geo_point"
},
"name": {
"type": "text",
"analyzer": "text_analyzer",
"search_analyzer": "ik_smart",
"copy_to": "all"
},
"pic": {
"type": "keyword"
},
"price": {
"type": "integer"
},
"score": {
"type": "integer"
},
"starName": {
"type": "keyword",
"copy_to": "all"
},
"all": {
"type": "text",
"analyzer": "text_analyzer",
"search_analyzer": "ik_smart"
},
"suggestion": {
"type": "completion",
"analyzer": "completion_analyzer"
}
}
}
}
GET /hotel/_search
{
"suggest": {
"suggestions": {
"text": "h",
"completion": {
"field": "suggestion"
}
}
}
}
实现数据库与ES之间的数据同步
同步修改
服务之间相互调用实现es文档数据的更新
缺点:慢,耦合高
优点:实现简单
通过消息队列进行异步修改 (推荐)
性能较高,低耦合,复杂度一般
配置一个TopicExchange 和两个队列 分别通过不同的routingkey 监听数据库更新的消息和数据库删除的消息
消费者:MQ配置、消息处理
生产者:发送消息逻辑
通过监听Mysql的BinLog完成es文档的更新
性能非常高,没有耦合,复杂度高且依赖数据库配置
十、Sentinel 微服务保护
在微服务架构中,某个服务的健康状态,可能会影响整个系统(雪崩问题)
为了解决这个问题,通常会引入线程隔离,流量控制以及熔断策略,来预防和避免该问题的发生
服务保护技术:Sentinel(阿里巴巴)、Hystrix(网飞公司,不再积极维护)
安装
1.下载Jar文件
https://github.com/alibaba/Sentinel/releases/
2.运行jar文件
java -jar -Dserver.port=8080
3.默认用户名密码都是sentinel,可以修改jar包中文配置文件
使用
1.引入Sentinel依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
2.配置
spring:
cloud:
sentinel:
transport:
dashboard: sentinel:9999
3.查看状态
对于配置好的服务,在接收第一个请求的时候,健康信息将会同步到sentinel后台。
限流 (预防措施)
流量控制用于调整网络包的发送数据。任意时间到来的请求往往是随机不可控的,而系统的处理能力是有限的,需要根据系统的处理能力对流量进行控制。Sentinel 作为一个调配器,可以根据需要把随机的请求限制QPS的最大值,保证服务健康运行。
流控模式:
- 直接:当api大达到限流条件时,直接限流(比如到达多少点击次数)
- 关联:当关联的资源到达阈值,就限流自己
- 链路:只记录指定路上的流量,指定资源从入口资源进来的流量,如果达到阈值,就进行限流,api级别的限流
流控效果:
快速失败:超出阈值,快速失败抛出异常
Warm Up:预热模式,适用于服务刚刚启动的场景,对于激增的流量,某些初始化操作可能耗时较久,可能会导出服务出现问题,预热模式可以让流量在随着时间推移慢慢增长,从而达到保护的作用。
排队等待:相对于快速失败,多了一条可以等待队列,但对于预计等待时间很长的请求仍然会失败操作,排队等待通常用于流量整形。
热点:
更细粒度的限流规则,可以根据请求参数进行限流,对于热点参数进行设置例外,接受更高的流量。
隔离和降级
对于微服务保护,限流所做的是预防服务出现问题,然而对于已经出现问题的服务,通常通过隔离降级来避免出现问题的服务影响到其他微服务。
隔离:
对于调用者配置对应业务的线程池,防止异常线程占用过多资源导致服务不可用
对于服务调用者的调用规则进行配置,服务调用往往通过feign进行实现,因此客户端必须配置feign和sentinel
1.配置feign客户端开启sentinel的功能
feign:
sentinel:
enabled: true
2.编写失败的逻辑
@Slf4j
public class UserClientFallbackFactory implements FallbackFactory<UserClient> {
@Override
public UserClient create(Throwable cause) {
return new UserClient() {
@Override
public User findById(Long id) {
log.error("UserClient: findById:" + cause);
return null;
}
};
}
}
@FeignClient(value = "user-service", fallbackFactory = UserClientFallbackFactory.class)
public interface UserClient {
@GetMapping("/user/{id}")
User findById(@PathVariable("id") Long id);
}
public class FeignConfig {
@Bean
public UserClientFallbackFactory userClientFallbackFactory() {
System.err.println("create UserClientFallbackFactory");
return new UserClientFallbackFactory();
}
}
@EnableFeignClients(basePackages = "com.wds",defaultConfiguration = FeignConfig.class)
public class OrderApplication {...}
熔断降级
对于异常比例较高的服务,进行熔断该服务,等到服务恢复重放行该服务的请求
三种状态:
- closed 熔断器关闭,放行所有请求,并监听请求的状态。
- open 开启,阻止请求的访问 快速失败。
- half-open 熔断时间结束,放行一次请求,如果成功,则关闭断路器。
熔断策略
- 慢调用比例 统计超时的调用请求的比例
- 异常比例 统计出现异常的请求的比例
- 异常数 统计异常数量
规则持久化
略
十一、分布式事务
事务的ACID原则
A 原子性:事务中的操作要么全成功,要么全部失败。
C 一致性:要保证数据库的完整性约束和一致性约束。
I 隔离性:对统一资源操作的事务不能同时发生。
D 持久性:对数据库的修改,将永久保存,不管是否出现故障。
分布式系统 - CAP理论
对于分布式系统
C 一致性: 用户访问任意的节点,得到的数据必须一致
A 可用性: 对于健康状态的服务,必须得到响应,不能超时或拒绝
P 分区容错性: 系统的服务出现分区时,整个系统也要持续对外服务
CAP的三个特性,无法同时满足,只能满足其中两个特性,对于CAP的取舍,从而又有了BASE理论
分布式系统 - BASE理论
基本可用性(Basicaly Available): 分布式系统出现故障时,允许损失部分可用性,即保证核心可用性。
软状态(Soft State):在一定时间内,允许出现短暂的不一致状态。
最终一致性(Eventually Consistent):虽然无法保证强的一致性,但在软状态结束后,最终要达到数据一致。
安装配置Seata
下载并解压,修改conf目录中的registry文件的配置
注册中心
type = "nacos"
nacos {
application = "seata-server"
serverAddr = "127.0.0.1:8848"
group = "DEFAULT_GROUP"
namespace = ""
cluster = "SH" # 一定要指定,不要用default,有BUG会导致IP问题
username = "nacos"
password = "nacos"
}
配置中心
type = "nacos"
nacos {
serverAddr = "127.0.0.1:8848"
namespace = ""
group = "SEATA_GROUP"
username = "nacos"
password = "nacos"
dataId = "seataServer.properties"
}
配置nacos中的对应配置:
seataServer.properties
# 数据存储方式,db代表数据库
store.mode=db
store.db.datasource=druid
store.db.dbType=mysql
store.db.driverClassName=com.mysql.jdbc.Driver
store.db.url=jdbc:mysql://127.0.0.1:3306/seata?useUnicode=true&rewriteBatchedStatements=true
store.db.user=root
store.db.password=123456
store.db.minConn=5
store.db.maxConn=30
store.db.globalTable=global_table
store.db.branchTable=branch_table
store.db.queryLimit=100
store.db.lockTable=lock_table
store.db.maxWait=5000
# 事务、日志等配置
server.recovery.committingRetryPeriod=1000
server.recovery.asynCommittingRetryPeriod=1000
server.recovery.rollbackingRetryPeriod=1000
server.recovery.timeoutRetryPeriod=1000
server.maxCommitRetryTimeout=-1
server.maxRollbackRetryTimeout=-1
server.rollbackRetryTimeoutUnlockEnable=false
server.undo.logSaveDays=7
server.undo.logDeletePeriod=86400000
# 客户端与服务端传输方式
transport.serialization=seata
transport.compressor=none
# 关闭metrics功能,提高性能
metrics.enabled=false
metrics.registryType=compact
metrics.exporterList=prometheus
metrics.exporterPrometheusPort=9898
随后恢复对应的数据库文件,启动bin目录中seata-server.bat,启动Seata服务即可。
服务整合Seata
对于需要使用seata的微服务,引入依赖
<seata.version>1.4.2</seata.version>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
<exclusions>
<exclusion>
<artifactId>seata-spring-boot-starter</artifactId>
<groupId>io.seata</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
<version>${seata.version}</version>
</dependency>
配置yml文件
seata:
registry:
type: nacos
nacos:
server-addr: nacos:8848
namespace: ""
group: DEFAULT_GROUP
application: seata-server
username: nacos
password: nacos
tx-service-group: seata-demo
service:
vgroup-mapping:
seata-demo: default
XA模式
XA模式:各个服务RM执行完成后,先不提交,由事务协调者TC判断状态后,统一提交或者回滚
优缺点:保留了数据库的ACID特性,同时也依赖数据库的事务特性。需要占用资源等待调用服务全部执行完成后,才能释放资源。
seata:
data-source-proxy-mode: XA #事务模式
对于需要启动全局事务的方法上添加 @GlobalTransactional 注解;
注意需要加到调用者的方法上,被调用的服务将会自动被管理,不需要为被调用的方法上添加。
AT模式
和XA模式的区别:事务执行完成后立即提交,锁定资源周期短。失败后回滚通过数据快照实现回滚。
XA是强一致性,AT是最终一致性。
缺点:中间阶段属于,软状态,属于最终一致
快照功能会影响性能,但是相比锁定占用资源性能好很多
快照存储在微服务的数据库中的undo_log表中
seata:
data-source-proxy-mode: AT #事务模式
TCC模式
TCC (try commit cancel) 模式,不会使用数据库的锁,执行之后立即提交,不会占用资源
一阶段:执行对应逻辑
二阶段:根据一阶段的状态,执行提交,或者回滚
注意点:空回滚(cancel)、悬挂(try)、幂等性(cancel)问题
TCC模式实现比较麻烦,需要实现TCC的三个逻辑,并创建对应的表来协调TCC的逻辑
DROP TABLE IF EXISTS `account_freeze_tbl`;
CREATE TABLE `account_freeze_tbl` (
`xid` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`user_id` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`freeze_money` int(11) UNSIGNED NULL DEFAULT 0,
`state` int(1) NULL DEFAULT NULL COMMENT '事务状态,0:try,1:confirm,2:cancel',
PRIMARY KEY (`xid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = COMPACT;
@LocalTCC
public interface AccountTCCService {
@TwoPhaseBusinessAction(name = "deduct", commitMethod = "confirm", rollbackMethod = "cancel")
void deduct(
@BusinessActionContextParameter(paramName = "userId") String userId,
@BusinessActionContextParameter(paramName = "money") int money);
boolean confirm(BusinessActionContext ctx);
boolean cancel(BusinessActionContext ctx);
}
@Service
@Slf4j
public class AccountTCCServiceImpl implements AccountTCCService {
@Resource
private AccountMapper accountMapper;
@Resource
private AccountFreezeMapper accountFreezeMapper;
@Override
public void deduct(String userId, int money) {
// 从Seata上下文中获取事务ID
String xid = RootContext.getXID();
// 悬挂
AccountFreeze suspensionFreeze = accountFreezeMapper.selectById(xid);
if (suspensionFreeze != null) {
return;
}
// 扣减余额,创建冻结对象,记录状态并存储
accountMapper.deduct(userId, money);
AccountFreeze accountFreeze = new AccountFreeze();
accountFreeze.setUserId(userId);
accountFreeze.setFreezeMoney(money);
accountFreeze.setState(AccountFreeze.State.TRY);
accountFreeze.setXid(xid);
accountFreezeMapper.insert(accountFreeze);
}
@Override
public boolean confirm(BusinessActionContext ctx) {
String xid = ctx.getXid();
int count = accountFreezeMapper.deleteById(xid);
return count == 1;
}
@Override
public boolean cancel(BusinessActionContext ctx) {
String xid = ctx.getXid();
AccountFreeze accountFreeze = accountFreezeMapper.selectById(xid);
// 空回滚
if (accountFreeze == null) {
AccountFreeze freeze = new AccountFreeze();
freeze.setXid(xid);
freeze.setState(AccountFreeze.State.CANCEL);
int count = accountFreezeMapper.insert(freeze);
return count == 1;
}
// 幂等性
if (accountFreeze.getState() == AccountFreeze.State.CANCEL) {
return true;
}
// 常规回滚
accountMapper.refund(accountFreeze.getUserId(), accountFreeze.getFreezeMoney());
accountFreeze.setFreezeMoney(0);
accountFreeze.setState(AccountFreeze.State.CANCEL);
int account = accountFreezeMapper.updateById(accountFreeze);
return account == 1;
}
}
将原有的service中的逻辑替换为TCC中的逻辑
sage模式
Saga模式是SEATA提供的长事务解决方案,分为两个阶段:
一阶段:直接提交本地事务
二阶段:成功什么都不做,失败则通过编写失败补偿业务来回滚
没有锁,没有隔离,会存在脏写
软状态持续时间不确定,时效性差
要编写状态机和补偿业务
Seata的高可用
需求在集群中的seata节点出现问题时,能够不重启服务,切换到其他集群
- 配置nacos中的集群配置文件 创建client.properties
# 事务组映射关系
service.vgroupMapping.seata-demo=SH
# 以下均为默认值
service.enableDegrade=false
service.disableGlobalTransaction=false
# 与TC服务的通信配置
transport.type=TCP
transport.server=NIO
transport.heartbeat=true
transport.enableClientBatchSendRequest=false
transport.threadFactory.bossThreadPrefix=NettyBoss
transport.threadFactory.workerThreadPrefix=NettyServerNIOWorker
transport.threadFactory.serverExecutorThreadPrefix=NettyServerBizHandler
transport.threadFactory.shareBossWorker=false
transport.threadFactory.clientSelectorThreadPrefix=NettyClientSelector
transport.threadFactory.clientSelectorThreadSize=1
transport.threadFactory.clientWorkerThreadPrefix=NettyClientWorkerThread
transport.threadFactory.bossThreadSize=1
transport.threadFactory.workerThreadSize=default
transport.shutdown.wait=3
# RM配置
client.rm.asyncCommitBufferLimit=10000
client.rm.lock.retryInterval=10
client.rm.lock.retryTimes=30
client.rm.lock.retryPolicyBranchRollbackOnConflict=true
client.rm.reportRetryCount=5
client.rm.tableMetaCheckEnable=false
client.rm.tableMetaCheckerInterval=60000
client.rm.sqlParserType=druid
client.rm.reportSuccessEnable=false
client.rm.sagaBranchRegisterEnable=false
# TM配置
client.tm.commitRetryCount=5
client.tm.rollbackRetryCount=5
client.tm.defaultGlobalTransactionTimeout=60000
client.tm.degradeCheck=false
client.tm.degradeCheckAllowTimes=10
client.tm.degradeCheckPeriod=2000
# undo日志配置
client.undo.dataValidation=true
client.undo.logSerialization=jackson
client.undo.onlyCareUpdateColumns=true
client.undo.logTable=undo_log
client.undo.compress.enable=true
client.undo.compress.type=zip
client.undo.compress.threshold=64k
client.log.exceptionRate=100
2.修改微服务读取nacos中的配置
seata:
config:
type: nacos
nacos:
server-addr: 127.0.0.1:8848
username: nacos
password: nacos
group: SEATA_GROUP
data-id: client.properties
重启微服务,现在微服务到底是连接tc的哪个集群,都统一由nacos的client.properties来决定了。
十二、分布式缓存
单点Redis存在的问题:
- 数据丢失问题 - redis数据持久化
- 并发能力问题 - 搭建主从集群,实现读写分离
- 存储能力问题 - 搭建分片集群,利用插槽机制实现动态扩容
- 故障恢复问题 - 利用Redis哨兵,实现健康监测和自动恢复
技术点:持久化、主从、哨兵、分片集群
Redis持久化
RDB模式
RDB全称Redis Database Backup file
简单来说就是把redis内存中的数据,都记录到硬盘当中,当redis故障重启后,从磁盘读取快照文件,恢复数据
默认情况下,redis服务在停机时(不是宕机)执行RDB操作
备份命令
save
# 由redis主进程来执行RDB,会阻塞所有命令
bgsave
# 子进程后台执行备份操作,不会阻塞命令
rdb的配置
#自动备份 900秒内如果至少有一个key被修改,则执行bgsave,如果是 save "" 表示禁用RDB
save 900 1
save 300 10
save 60 10000
rdbcompression no # 是否压缩 压缩消耗CPU,节省磁盘空间
dbfilename dump.rdb #文件存储名称
dir ./ #文件保存目录
bgsave为什么不会影响数据的写入?
对页表进行fork,并设为只读,新写入的数据需要复制出一份新的,操作新的数据,旧数据用于备份
AOF模式
AOF Append Only File(追加文件)
redis 每次操作都会记录到aof文件中,可以看作日志文件,但是相对于日志文件,aof可以对日志进行压缩,去掉无意义的操作记录
aof默认是关闭的,需要修改配置来开启,以下是关于aof操作的配置
appendonly yes
appendfilename "appendonly.aof"
# aof文件记录的频率, 立即记录到文件/每秒记录一次/由操作系统决定
appendfsync always / everysec (默认) / no
aof相关命令
bgrewirteaof
# 将aof文件中的命令进行压缩,用最少的命令,达到相同的效果
# 设置自动执行机制
auto-aof-rewrite-parcentage 100 #体积增长100%后执行
auto-aof-rewrite-min-size 64mb #体积增长多少后执行
Redis主从
启动多个redis节点,对于从节点执行slaveof,指定主节点,通过主从分离能够显著提高读取性能
相关命令
slaveof 主节点ip 主节点端口
slaveof no one (脱离从节点状态)
<strong>注意</strong>:在5.0以后新增命令replicaof,与salveof效果一致。
# 无法访问 检查配置文件
bind 0.0.0.0 -::
protected-mode no
配置文件
bind 0.0.0.0 -::
protected-mode no
port 6379
dbfilename dump.rdb
rdb-del-sync-files no
dir ./
pidfile /var/run/redis_7001.pid
appendonly no
appendfilename "appendonly.aof"
appenddirname "appendonlydir"
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
aof-use-rdb-preamble yes
aof-timestamp-enabled no
tcp-backlog 511
timeout 0
tcp-keepalive 300
daemonize no
loglevel notice
logfile ""
databases 16
always-show-logo no
set-proc-title yes
proc-title-template "{title} {listen-addr} {server-mode}"
locale-collate ""
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
replica-serve-stale-data yes
replica-read-only yes
repl-diskless-sync yes
repl-diskless-sync-delay 5
repl-diskless-sync-max-replicas 0
repl-diskless-load disabled
repl-disable-tcp-nodelay no
replica-priority 100
acllog-max-len 128
lazyfree-lazy-eviction no
lazyfree-lazy-expire no
lazyfree-lazy-server-del no
replica-lazy-flush no
lazyfree-lazy-user-del no
lazyfree-lazy-user-flush no
oom-score-adj no
oom-score-adj-values 0 200 800
disable-thp yes
slowlog-log-slower-than 10000
slowlog-max-len 128
latency-monitor-threshold 0
notify-keyspace-events ""
hash-max-listpack-entries 512
hash-max-listpack-value 64
list-max-listpack-size -2
list-compress-depth 0
set-max-intset-entries 512
set-max-listpack-entries 128
set-max-listpack-value 64
zset-max-listpack-entries 128
zset-max-listpack-value 64
hll-sparse-max-bytes 3000
stream-node-max-bytes 4096
stream-node-max-entries 100
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit replica 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
dynamic-hz yes
aof-rewrite-incremental-fsync yes
rdb-save-incremental-fsync yes
jemalloc-bg-thread yes
使用Docker配置集群,需要使用自定义镜像,让redis启动时指定配置文件,默认镜像无法启动。
FROM redis
COPY redis.conf /usr/local/etc/redis/redis.conf
CMD [ "redis-server", "/usr/local/etc/redis/redis.conf" ]
Redis哨兵集群
配置sentinel集群和redis集群,sentinel集群监控redis集群的健康,指挥redis的主从选举。
配置yml
spring:
redis:
sentinel:
master:mymaster
nodes:
- 192.168.150.101:27001
- 192.168.150.101:27002
- 192.168.150.101:27003
配置redis写操作指定到主节点
Redis分片集群
分片集群需要的服务器数量较多。
是Redis6版本之前,
是Redis6版本以后,集群管理以及集成到了redis-cli中,格式如下:
redis-cli --cluster create --cluster-replicas 1 192.168.150.101:7001 192.168.150.101:7002 192.168.150.101:7003 192.168.150.101:8001 192.168.150.101:8002 192.168.150.101:8003
命令说明:
redis-cli --cluster或者./redis-trib.rb:代表集群操作命令create:代表是创建集群--replicas 1或者--cluster-replicas 1:指定集群中每个master的副本个数为1,此时节点总数 ÷ (replicas + 1)得到的就是master的数量。因此节点列表中的前n个就是master,其它节点都是slave节点,随机分配到不同master
通过命令可以查看集群状态:
redis-cli -p 7001 cluster nodes
集群操作时,需要给redis-cli加上-c参数
redis-cli -c -p 7001
十三、微服务系统MQ
问题:
- 消息可靠性:如何确保消息至少被消费一次
- 延迟消息问题:如何实现消息的延迟投递
- 高可用问题:如何避免单点的MQ故障问题
- 消息堆积:如何解决消息堆积,无法及时消费的问题

 提供强力驱动
提供强力驱动 {kind=link}