Linux学习笔记
Linux,全称GNU/Linux,是一种免费使用和自由传播的类UNIX操作系统
Linux
Vim的使用
yy 复制当前行 (复制5行 5yy)
dd 删除当前行 (删除5行 5dd)
u 撤回
p 粘贴
/text 查找"text"文本并高亮显示
回车进入查找模式后 按 n 查找下一个
shift + N 查找上一个
:nohl 取消高亮
:set nu / :set noun 显示/隐藏行号
- gg/G / nG 快速定位到第一行/最后一行/第n行
系统操作
shutdown -h now # 关机
halt # 关机
shutdown -h 1 # 1分钟后关机
shutdown # 默认一分钟后关机
shutdown -r now # 重启
reboot # 重启
sync # 将内存中的数据写到硬盘,默认关机重启会执行
用户管理
组的概念: 将多个用户放到同一个组可以对组进行统一的权限管理,管理更加便捷
当一个用户没有添加到任何组时,系统默认生成一个和用户名一样的一个组
- useradd 用户名 添加一个用户
- useradd -d 文件夹名 用户名 添加用户并指定用户的目录
- useradd -g 组名 用户名 创建用户并且添加到指定的组内
- passwd 用户名 修改对应用户名的密码 如果没有指定用户名,将会修改当前用户的密码
- su 用户名 切换至指定用户
- su - 用户名 切换至指定用户(和环境一起)
- userdel 用户名 删除用户
- userdel -r 用户名 删除指定用户 并且删除用户的遗留文件
- id 用户名 查看该用户的一些信息(最后一次登录时间和对应的ip,用户所属的组和用户id)
- who am i 查看当前会话的第一次登录的用户
- groupadd 组名 添加一个组
- groupdel 组名 删除已经存在的组
- usermod -g 组名 用户名 将用户添加到组内
系统运行级别
- 运行级别分7级
- 0 关机
- 1 单用户无网络
- 2 多用户无网络
- 3 多用户有网络
- 4 系统预留
- 5 图形界面
- 6 重启
- 单用户环境常用来修改root密码
- init 0 切换到0的系统运行级别
- systemctl get-default 获取当前的运行级别
- systemctl set-default graphical.target 设置默认的运行级别为图形化
- multi-user.target多用户含网络的运行级别
文件操作
- cd 目录操作
- touch 创建空文件
- rmdir 删除文件夹但是必须是空的才能删除成功
- mkdir 穿件文件夹 参数p 标识父级(parent)文件夹不存在的时候同时创建父级文件夹
- rm 参数r 递归删除用于删除目录 参数f 表示FALSE 不提示是否确认删除
- pwd 显示当前的路径
- cp 复制文件或目录 \cp 不提示覆盖 cp -r 复制整个目录(递归复制)
- mv 移动/重命名
- tail -f filename 对文件追踪显示多用与查看日志
- more 滚动查看文件内容
- less 滚动查看文件内容,但是不会加载全部文件到内存,适合打开大文件
- cat 查看
- echo 输出 echo $环境变量名 输出环境变量的值
- '>' 输出重定向(覆盖) ‘>>’ 输出重定向(追加)
- history 命令历史 history 10 显示最近显示的10条
- date 日期 “+%Y-%m-%d %H:%M:%S”
- cal 日历 cal 2023 查看2023年整年的日历
- find 查找路径 查找文件的命令 -name 按文件名查找 -user 按拥有者查找 -size按照文件大小查找 (k,M,G) + - 不写是等于
- locate 按照索引查找,速度更快但是要提前创建索引 updatedb 更新索引
- which 查看命令存在的位置
权限操作
文件标识 - 文件 d 目录 c 字符设备 (各种硬件) b 块设备(硬盘)
| 标识 | 文件 | 文件夹 |
|---|---|---|
| r(4) | 可读 | 可查看内容 ls |
| w(2) | 可写 | 可操作文件夹内的结构(删除新增文件) |
| x(1) | 可执行 | 可以进入目录 cd |
chown 用户 文件名 修改文件的所有者 -r 递归
- chown 用户:组 文件名 修改文件的所有者和所在组
chgrp 组名 文件名 修改文件的所有组 -r 递归
chmod 权限 文件 书写格式
- u 所有者 g 所有组 o 其他组 a 全部 chmod u=rwx,g=rx,o=rx file
- u+w u-w 给所有者增加减少权限 chmod u+w file
- 数字 r4 w2 x1 chmod 777 file
定时任务
crontab -e 编辑任务列表
任务格式 : * * * * *
分别代表:分钟 小时 日 月 周
例如 : */1 * * * * 每分钟执行一次
特殊符号: / 每 ,和 - 至
at 一次性的定时任务
atrm 编号 删除定时任务
磁盘操作
- lsblk 列出块设备的信息 参数 f 显示文件系统信息
- df 显示磁盘信息 占用情况 -h 以可读性较高的方式显示
- du 显示指定目录的文件占用情况 -h 可读性较好的单位 --max-depth=1 子目录深度 -a 包含文件
- fdisk /dev/sda 对指定的块设备 操作,分区
- mkfs 创建文件系统
- mount 块设备分区文件 挂载的目录 挂载linux系统外的设备 (临时挂载,重启失效)
- umount 断开挂载的设备 可以跟设备也可以跟具体的挂载点
- 持久化挂载,修改/etc/fstab 文件的内容调整挂载设置
vm虚拟机的网络
NAT模式 通过nat的方式和主机共享ip,生成一个虚拟的网关服务,主机和虚拟机都会链接到这个网关,虚拟网关通过服务的方式代理nat网段内的所有设备访问真实主机的网络
桥接模式 通过生成一个虚拟的(集线器,交换机)将虚拟机直接链接到真实主机的网路链路上,此时虚拟机在局域网内是可见的,会占用真实局域网的ip
仅主机模式 主机与虚拟机通过网卡互联,不能上网
修改虚拟的ip地址 修改vim /etc/sysconfig/network-scripts/ifcfg-网卡名称中的配置
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static //静态ip
IPADDR="192.168.6.100" //ip地址
NETMASK="255.255.255.0" //子网掩码
GATEWAY="192.168.6.1" //网关
DNS1="192.168.6.1" //dns
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=default
NAME=ens160
UUID=4ded5bf3-4709-4de5-a0eb-4eb41f04cd81
DEVICE=ens160
ONBOOT=yes //开机时启用
进程相关
- top 显示或管理执行中的程序
- -i 仅显示活跃进程
- -d 指定刷新的秒数
- -p 指定监视进程的id
- ps 进程状态 -a 显示所有终端的进程 -u 以用户的形式展示 -x 显示后台进程的运行时参数
- ps -aux
- ps -ef 全格式查看当前所有进程
- kill 8888 终止进程PID为8888的进程
- -9 强制终止
- 可以强制其他用户下线 可以临时停用远程登录sshd
- killall 终止进程和子进程
- pstree -up 树状展示当前运行的进程
- ntsysv 图形化管理服务
- netstat 查看系统网路状况
- -an 显示详细信息
- -l 只显示端口
防火墙
- netstat -anp 查看linux系统中的网络状态 可用排查端口号冲突
- firewall-cmd -permanent --add-port=端口/协议
- firewall-cmd -permanent --remove-port=端口/协议
- firewall-cmd --reload 重新载入火墙规则
- firewall-cmd -query-port=端口号/协议
RPM包管理工具
rpm -qa 查询所有
rpm -q name 查询软件包name
rpm -qi 查询软件包的信息
rpm -ql 查询软件包的文件
rpm -qf 文件路径 查询文件所属的软件包
rpm -ivh (rpm文件) 安装对应的rpm文件
- i install 安装
- v verbose 显示提示信息
- h hash 显示进度条
环境变量
linux下配置环境变量通过修改 /etc/profile 文件实现
export JAVA_HOME=/......./
PATH=$JAVA_HOME/bin
- export是真正意义上的环境变量,不加export是bash变量,但是在PATH中引入了bash变量效果是相同的
- 修改完后 source /etc/profile生效
- 使用 echo $PATH 查看是否配置正确
- = 左右不要有空格,否则将会出现错误
shell 编程
- 指定解释器,文件首行
#!/bin/bash ''表示字符串#单行注释:<<!!多行注释且独占一行$引用变量unset销毁变量readonly只读变量,不可销毁- ``反引号表示命令
- 位置参数 执行时传参
- $n 拿到第n个位置参数 但是如果超过10个要${10}
- $* 所有参数,所有参数看为一个整体
- $@ 所有参数,分开对待每个参数 输出和$*相似
- $# 参数数量
- 预定义变量
- $$ 当前脚本的PID
- $! 最后一个进程的PID
- $? 上一次命令的执行状态 0为正常
- shell 表达式
- `expr 1+1 `
- $(1+1)
- $[1+1]
- 条件判断
字符串
- = 是否相同
整数
- -lt 小于
- -le 小于等于
- -eq 等于
- -gt 大于
- -ge 大于等于
- -ne 不等于
权限
- -r 读取
- -w 写入
- -x 执行
文件类型
- -f 文件存在
- -e 文件或者目录存在
- -d 目录存在
- 判断语句
- if [ 表达式 ] then 执行语句 fi 非空返回true
- 使用示例 [表达式] && echo ok ||echo "not ok"
echo
打印命令,使用方式
echo # 输出一个空行
echo hello # 输出hello并换行
echo -n hello # 输出hello
# 调用变量
name=zhangsan
echo $name
# 打印上一个程序的退出状态码
echo $? # 0是成功执行正常退出,非0就是有意外情况
# 查看上一条命令的执行详情
echo !!
# 查找某条命令的执行详情
echo !l # 最近一条以l开头的命令
如何打印 特殊字符 如 $
echo \$name
echo '$name'
特殊情况 旧版redhat系发行版可能会触发
echo "hello world!"
# 报错,搜寻以”开头的命令找不到
-e 参数 开启转义
echo -e "hello\nworld"
bash
Linux 命令解释器 运行在文本窗口中执行用户命令
其工作方式类似python解释器
命令行展开
通过{}使用 例子:
echo {1..100}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100
echo {1..100}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100
echo {a..z}
a b c d e f g h i j k l m n o p q r s t u v w x y z
命令别名
alias # 展示全部别名
alias grep='grep --color=auto'
alias l='ls -CF'
alias la='ls -A'
alias ll='ls -l'
alias ls='ls --color=auto'
alias rm='rm -i' # 新增命令别名
unalias rm # 删除命令别名
命令回溯
history # 展示命令历史
!行号 #重复执行命令中的某一行
!! #重复执行上次命令
bash快捷键
ctrl + a # 光标到行首
ctrl + e # 光标到行首
ctrl + k # 删除后面的命令
ctrl + u # 删除前面的命令
ctrl + l # 清屏
命令补全& 文件路径补全
按tab建 补全PATH中存在的命令 或者 文件目录
RegExp 正则表达式
Regular Expression: 正则表达式
通过符号的辅助,快速过滤、替换、处理所需的字符串
特点:
- 正则表达式是一套规则和方法
- 正则工作以行为单位,一次处理一行
- 在linux中通常只有 sed grep awk支持
Linux三剑客 三个比较重要的linux名称
- sed 文本编辑器
- awk 格式化文本
- grep 文本过滤器
正则表达式的分类 (三剑客中的分类)
基本正则表达式 BRE
如 ^$.[]*扩展正则表达式 ERE
在BRE基础上新增了 (){}?+|等
基本正则表达式的功能:
- 匹配字符
- 匹配次数
- 位置锚定
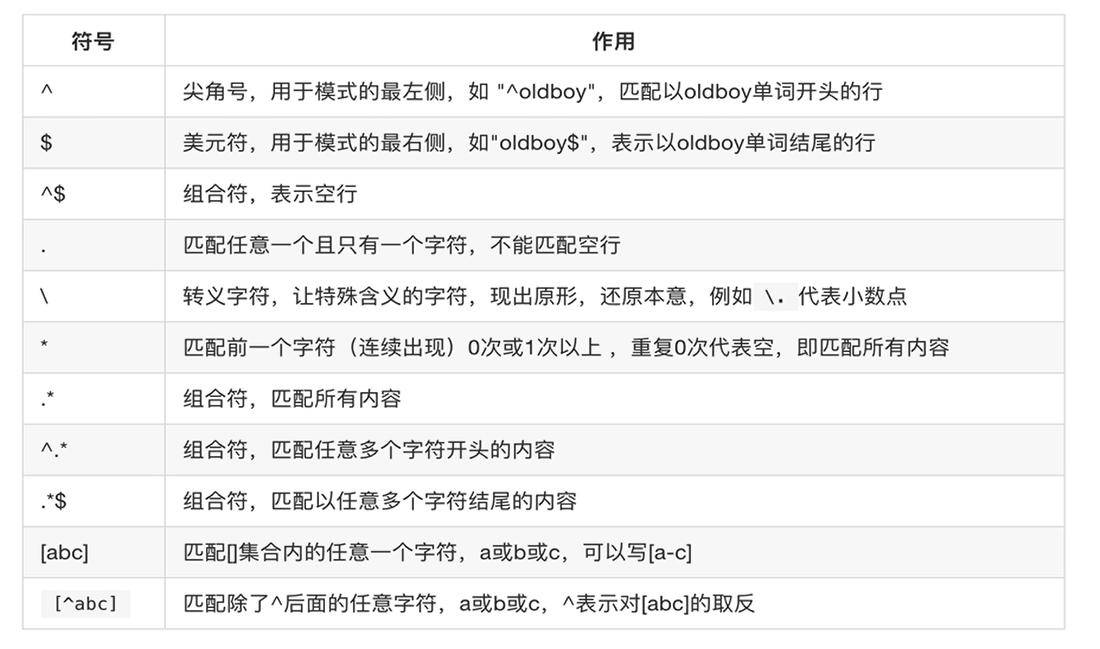
基本正则表达式:
扩展表达式需要 grep -E(启用拓展)才能使用
| 字符 | 作用 |
|---|---|
| + | 匹配一个字符一次以上 |
| [:/]+ | 匹配 : 或 / 一次以上 |
| ? | 匹配字符0或者1次 |
| | | 或者的意思 |
| ( ) | 分组过滤,被包裹的内容是一个整体 |
| a{1,2} | 匹配字符 1-2次 |
| a{1,} | 1次以上 |
| a{1} | 一次 |
| a{,2} | 0-2次 |
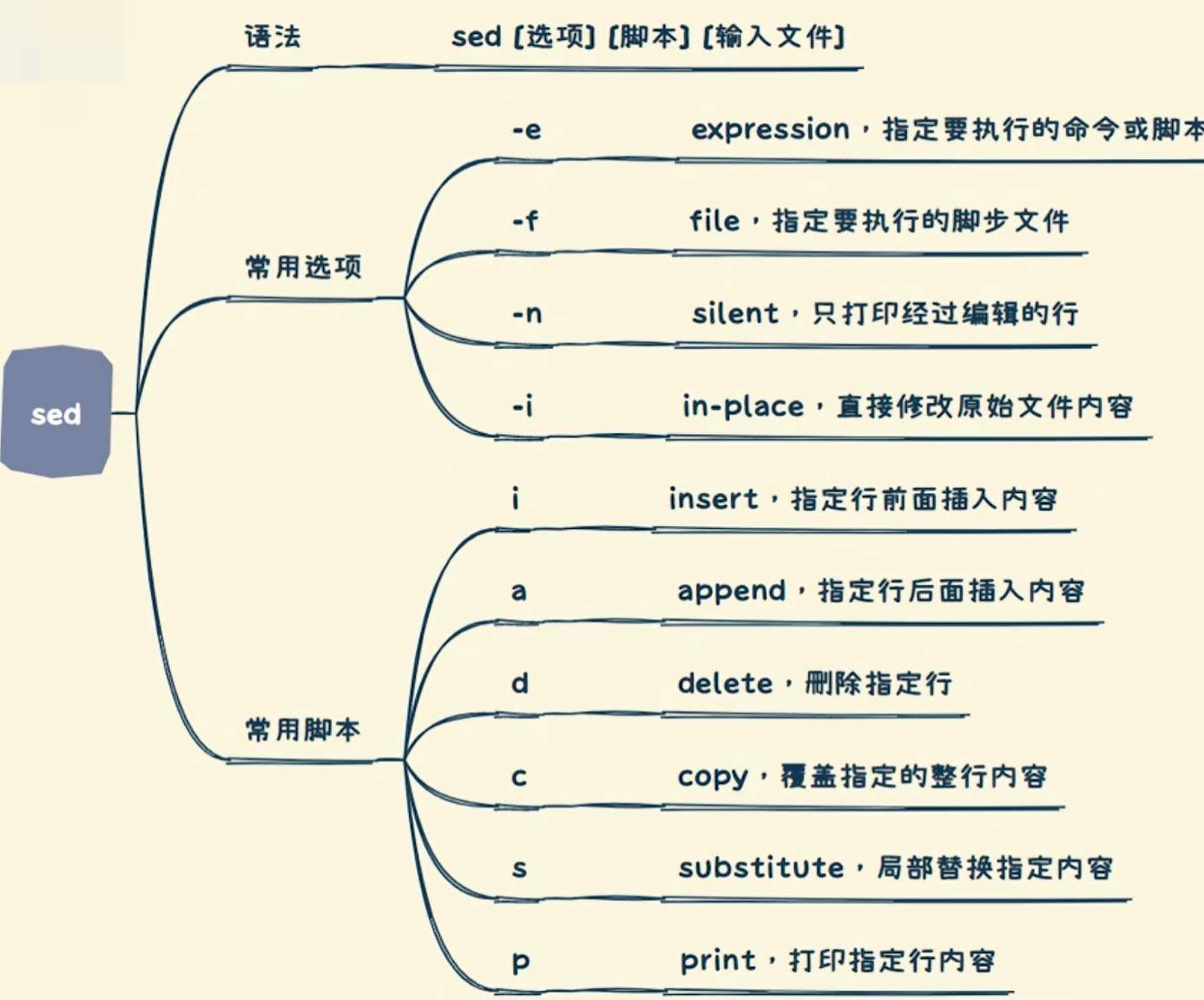
sed (steam editor)
流式编辑器,流式代表一行一行的进行处理
使用方式
sed -e (表达式) 文件 可同时写多个-e参数,执行多次
也可以将表达式写入到文件中, 通过-f参数将文件的脚本内容读入并执行
默认只是打印出来,通过-i参数即可写入修改
通过 -ie 可以写入并备份原有文件
对于文本,常用操作包含以下四种
- 新增
- 删除
- 修改
- 查询
假定文件test内容
1
2
3
4
5
表达式书写
[行条件] 操作 \ 内容
行条件不写就是所有行生效
增操作
a ,append 追加,在指定行后新增一行
sed -e '1a\new line' test
1
new line
2
3
4
5
i, insert插入,在指定行前新增一行
sed -e '1i\new line' test
new line
1
2
3
4
5
删操作
d,delete 删除指定行
sed -e '1d' test'
2
3
4
5
修改操作
c, 改变某行
sed -e '1c\test change line' test
test change line
1
2
3
4
5
s,替换对应行的一个或者多个字符串为目标字符串 (最常用,且支持正则表达式)
test内容:
top line
a new line
new new line
修改局部(每行最多只替换一个):
sed 's/new/old/' test
top line
a old line
old new line
修改多个(有几个替换几个):
sed 's/new/old/g' test
top line
a old line
old old line
查询操作 (打印)
p 输出对应行
sed '1p' test
top line
top line
a new line
new new line
在输出的过程中,p的输出和sed的默认输出缓冲区内容会冲突,出现重复输出的现象
通过-n 参数来关闭缓冲区输出,只输出我们指定的行
sed -n '1p' test
top line
总结
sed 补充 (配合正则)
sed的表达式中的配置行部分可以使用正则进行匹配,将成功匹配的行进行处理
sed -r 启用正则扩展

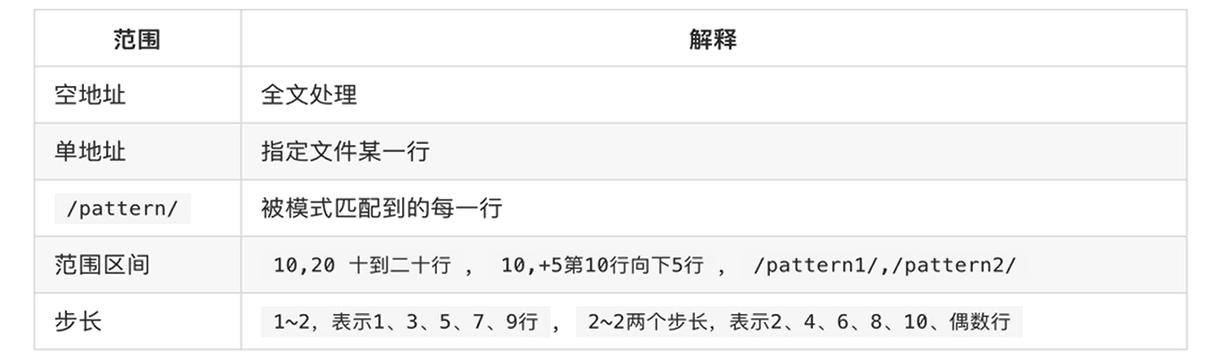

grep
Linux grep (global regular expression) 命令用于查找文件或者管道数据流里符合条件的字符串或正则表达式。
语法
grep [options] pattern [files]
或
grep [-abcEFGhHilLnqrsvVwxy][-A<显示行数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...]
- pattern - 表示要查找的字符串或正则表达式。
- files - 表示要查找的文件名,可以同时查找多个文件,如果省略 files 参数,则默认从标准输入中读取数据。
常用选项::
-E:启用扩展正则 extend-o:只显示匹配到的字符串本身 only-i:忽略大小写进行匹配 ignore-v:反向查找,只打印不匹配的行-n:显示匹配行的行号 number-c:打印匹配的行数量
分组语法()
将多个字符捆绑在一起,当作一个整体进行处理
(was|ad) (捆绑)匹配was或者wad
(was).*\1 (复用)\1重复引用第一个分组
awk
awk 原名 gawk , 通常用于处理文本格式时使用,其实它还是一个编程语言(Crazzy!)。
基础
awk语法:
awk options parttern {action} file
参数 模式 动作
引用字段:
$0:表示整行文本。$1:表示第一字段。$2:表示第二字段,依此类推。$NF: 表示最后一列
在 awk 中,字段是根据字段分隔符(field separator)来区分的。默认情况下,awk 使用空格或制表符作为字段分隔符,但你可以通过设置 FS 变量来指定其他分隔符。
awk '{ print $1, $2, $3 }' data.txt
# 打印每一行的第一列 第二列 第三列。
awk 'BEGIN {FS = ","} {print $2}' test
# 指定以逗号分隔字段。
exmaple
# ens33 的ipv4地址
ip addr show ens33 | awk 'NR==4 {print $2}' | awk 'BEGIN {FS="/"} {print $1}'
192.168.6.66
# ens33 的ipv4地址 (正则方式)
ip addr show ens33 | awk '/inet / {print $2}' | awk 'BEGIN {FS="/"} {print $1}'
192.168.6.66
# 所有的ipv4地址
ip addr | awk '/inet / {print $2}' | awk 'BEGIN {FS="/"} {print $1}'
127.0.0.1
192.168.6.66
172.17.0.1
# 所有的ip地址
ip addr | awk '/inet/ {print $1": "$2}' | awk 'BEGIN {FS="/"} {print $1}'
inet: 127.0.0.1
inet6: ::1
inet: 192.168.6.66
inet6: fe80::20c:29ff:fed8:bcf0
inet: 172.17.0.1

 提供强力驱动
提供强力驱动